반응형
- [혼공머신 11기] 1주차 스터디 및 과제
- [혼공머신 11기] 2주차 스터디 및 과제
- [혼공머신 11기] 3주차 스터디 및 과제
- [혼공머신 11기] 4주차 스터디 및 과제
- [혼공머신 11기] 5주차 스터디 및 과제
6주차 후기
드디어 혼공머신 11기 마지막주이다.
설 연휴 때 공부를 하고나서 한참 뒤에 내용을 정리하여 후기를 쓰려니 기억이 잘 나지 않는다.
어렴풋이 '드디어 딥러닝이라는 것을 해보는구나'라는 감정과 '뉴런이란게 이런거였구나' 싶은 느낌 정도만 어렴풋이 기억에 남는다.
혼공학습단 11기 학습회고도 써야하니 이번주 후기는 짧게 마무리 해야겠다.
6주차 과제
기본 미션 : 07-1 확인 문제 풀고, 풀이 과정 정리하기

선택 미션 : 07-2 확인 문제 풀고, 풀이 과정 정리하기


딥러닝을 시작합니다
인공 신경망
패션 MNIST
- 불꽃 데이터셋(머신러닝) / MNIST 데이터셋(딥러닝)
- 머신러닝과 딥러닝을 처음 배울 때 많이 사용하는 데이터셋
- 손으로 쓴 0~9까지의 숫자로 이루어져 있다.
- 패션 MNIST
- MNIST 데이터셋과 크기, 개수가 동일하지만 숫자 대신 패션 아이템으로 이루어진 데이터셋
- 패션 MNIST의 타깃은 0~9까지의 숫자 레이블로 구성된다.
- 0 : 티셔츠
- 1 : 바지
- 2 : 스웨터
- 3 : 드레스
- 4 : 코트
- 5 : 샌달
- 6 : 셔츠
- 7 : 스니커즈
- 8 : 가방
- 9 : 앵클 부츠
# 텐서플로의 케라스(Keras) 패키지를 임포트하고, 패션 MNIST 데이터 다운로드
from tensorflow import keras
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz 29515/29515 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz 26421880/26421880 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz 5148/5148 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz 4422102/4422102 [==============================] - 0s 0us/step
# 데이터 크기 확인
print(train_input.shape, train_target.shape)
print("=> 훈련 데이터는 60,000개의 이미지이고, 각 이미지는 28 x 28 크기이다.")(60000, 28, 28) (60000,) => 훈련 데이터는 60,000개의 이미지이고, 각 이미지는 28 x 28 크기이다.
# 테스트 세트 크기 확인
print(test_input.shape, test_target.shape)
print("=> 테스트 세트는 10,000개의 이미지로 이루어져 있다.")(10000, 28, 28) (10000,) => 테스트 세트는 10,000개의 이미지로 이루어져 있다.
# 훈련 데이터 첫 10개 이미지 출력
import matplotlib.pyplot as plt
fig, axs = plt.subplots(1, 10, figsize=(10, 10))
for i in range(10):
axs[i].imshow(train_input[i], cmap='gray_r')
axs[i].axis('off')
plt.show()
# 훈련 데이터 첫 10개의 타깃값 출력
print([train_target[i] for i in range(10)])[9, 0, 0, 3, 0, 2, 7, 2, 5, 5]
# 각 레이블 당 개수 출력
import numpy as np
print(np.unique(train_target, return_counts=True))(array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint8), array([6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000]))
로지스틱 회귀로 패션 아이템 분류하기
- 데이터가 큰 훈련 샘플(60,000개) → 샘플을 조금씩 꺼내서 모델을 훈련하는 방법이 더 효율적 → 확률적 경사 하강법(SGDClassifier)
- SGDClassifier을 사용하려면 1차원 배열로 변환해야 한다.
# 데이터 전처리 - 픽셀은 0~255 사이의 정수값이므로 255로 나누어 0~1 사이의 값으로 정규화
train_scaled = train_input / 255.0
# SGDClassifier 사용을 위해 1차원 배열로 변환
train_scaled = train_scaled.reshape(-1, 28*28)
# 변환된 train_scaled의 크기
print(train_scaled.shape)(60000, 784)
# 확률적 경사 하강법으로 교차 검증하여 성능 확인
from sklearn.model_selection import cross_validate
from sklearn.linear_model import SGDClassifier
sc = SGDClassifier(loss='log_loss', max_iter=5, random_state=42)
scores = cross_validate(sc, train_scaled, train_target, n_jobs=1)
print(np.mean(scores['test_score']))/usr/local/lib/python3.10/dist-packages/sklearn/linear_model/_stochastic_gradient.py:702: ConvergenceWarning: Maximum number of iteration reached before convergence. Consider increasing max_iter to improve the fit. warnings.warn( /usr/local/lib/python3.10/dist-packages/sklearn/linear_model/_stochastic_gradient.py:702: ConvergenceWarning: Maximum number of iteration reached before convergence. Consider increasing max_iter to improve the fit. warnings.warn( /usr/local/lib/python3.10/dist-packages/sklearn/linear_model/_stochastic_gradient.py:702: ConvergenceWarning: Maximum number of iteration reached before convergence. Consider increasing max_iter to improve the fit. warnings.warn( /usr/local/lib/python3.10/dist-packages/sklearn/linear_model/_stochastic_gradient.py:702: ConvergenceWarning: Maximum number of iteration reached before convergence. Consider increasing max_iter to improve the fit. warnings.warn( 0.8196000000000001 /usr/local/lib/python3.10/dist-packages/sklearn/linear_model/_stochastic_gradient.py:702: ConvergenceWarning: Maximum number of iteration reached before convergence. Consider increasing max_iter to improve the fit. warnings.warn(
인공 신경망(ANN, Artificial Neural Network)
- 기존의 머신러닝 알고리즘이 잘 해결하지 못했던 문제에서 높은 성능을 방뤼하는 새로운 종류의 머신러닝 알고리즘
- 인공 뉴런은 생물학적 뉴런의 모양을 본뜬 수학 모델에 불과하다.
- 가장 기본적인 인공 신경망 = 확률적 경사 하강법을 사용하는 로지스틱 회귀
- 매컬러-피츠 뉴런
- 1943년 워런 매컬러(Warren McCulloch)와 월터 피츠(Walter Pitts)가 제안한 뉴런 모델
- 텐서플로 : 가장 인기가 높은 딥러닝 라이브러리
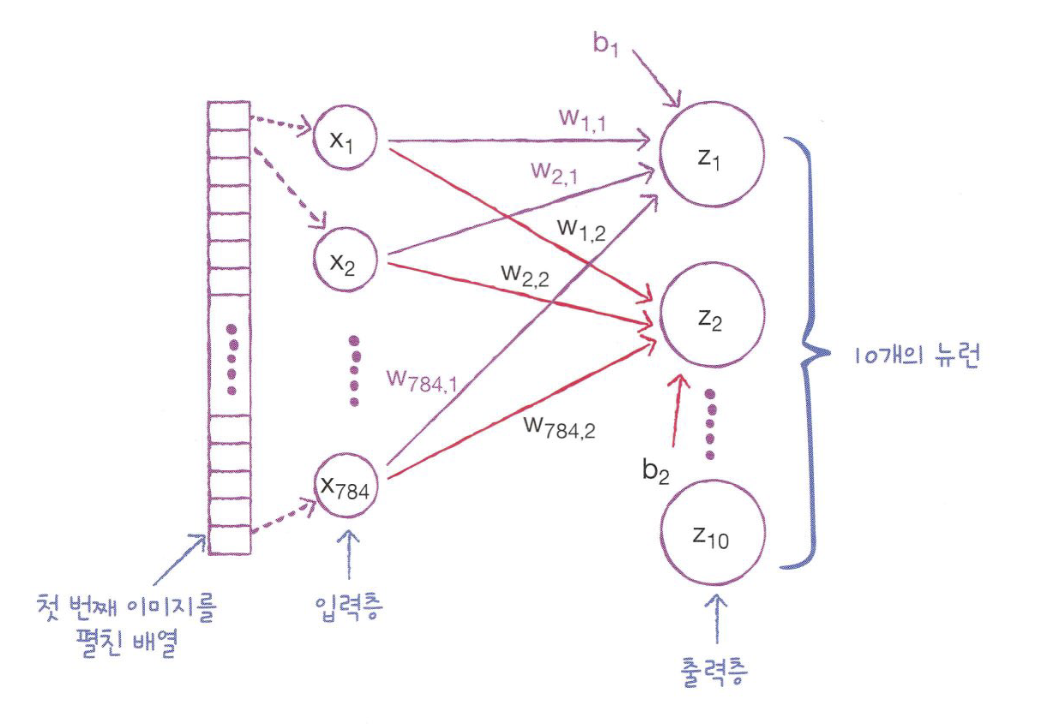
- 출력층(output layer)
- z1~z10
- 패션 MNIST 예제에서는 총 10개의 클래스이기 때문에 z10까지 계산
- 신경망의 최종 값을 만듬
- 뉴런(neuron) / 유닛(unit)
- z 값을 계산하는 단위
- 입력층(input layer)
- x1~x784
- 패션 MNIST 예제에서는 픽셀값 자체이고, 특별한 계산은 수행하지 않음
- 가중치
- z1을 만들기 위해 픽셀1인 x1에 곱해지는 가중치 = w1.1
- z2를 만들기 위해 픽셀1인 x1에 곱해지는 가중치 = w1.2
- 절편
- 뉴런마다 하나씩 순서대로 b1, b2와 같이 나타냄
텐서플로
- 구글이 2015년 11월 오픈소스로 공개한 딥러닝 라이브러리
- 저수준 API와 고수준 API가 존재
- 딥러닝 라이브러리 vs 다른 머신러닝 라이브러리
- 딥러닝 라이브러리는 GPU를 사용하여 인공 신경망을 훈련한다.
- GPU는 벡터와 행렬 연산에 최적화되어 있어 곱셈, 덧셈이 많이 수행되는 인공 신경망에 유리하다.
케라스(Keras)
- 2015년 3월 프랑소아 숄레(Francois Chollet)가 만든 딥러닝 라이브러리
- 텐서플로의 고수준 API
- 현재는 멀티-백엔드 케라스는 더 이상 개발되지 않고, 케라스는 텐서플로의 핵심 API가 되었다. 즉,
텐서플로=케라스가 되었다.
from tensorflow import keras인공 신경망으로 모델 만들기
- 인공 신경망에서는 교차 검증을 사용하지 않고, 검증 세트를 별도로 덜어내어 사용한다.
- 이유 1) 딥러닝 분야의 데이터셋은 충분히 크기 때문에 검증 점수가 안정적
- 이유 2) 교차 검증을 수행하기에는 훈련 시간이 너무 오래 걸림
# 검증 세트 분리하기
from sklearn.model_selection import train_test_split
train_scaled, val_scaled, train_target, val_target = train_test_split(train_scaled, train_target, test_size=0.2, random_state=42)
print(train_scaled.shape, train_target.shape)
print(val_scaled.shape, val_target.shape)(48000, 784) (48000,) (12000, 784) (12000,)
# 밀집층 생성
dense = keras.layers.Dense(10, activation='softmax', input_shape=(784,))- 밀집층(dense layer) / 완전 연결층(fully connected layer)
- 양쪽 뉴런이 모두 연결되어 있는 부분
- 패션 MNIST 예제에서 784개의 픽셀과 10개의 뉴런이 연결된 선 (총 7,840개)
- 케라스의 Dense 클래스를 사용하여 만들 수 있다.
# 신경망 모델 생성
model = keras.Sequential(dense)
위 그림은 지금까지 만든 신경망을 나타낸다.
- 오른쪽 마지막 부분 출력층에
소프트맥스 함수적용 - 소프트맥스와 같이 뉴런의 선형 방정식 계산 결과에 적용되는 함수를
활성화 함수라고 한다. - 출력층에 적용하는 활성화 함수는 제한적이다.
- 이진 분류 : 시그모이드 함수
- 다중 분류 : 소프트맥스 함수
인공 신경망으로 패션 아이템 분류하기
- 케라스 모델은 훈련하기 전에 model 객체의 compile() 메서드를 수행하고, 이때 손실 함수의 종류를 지정해야 한다.
- 원-핫 인코딩(one-hot encoding) : 타깃값을 해당 클래스만 1이고, 나머지는 0인 배열로 만드는 것
sparse_categorical_crossentropy: 원-핫 인코딩을 하지 않고, 정수로 된 타깃값을 사용해 크로스 엔트로피 손실을 계산하는 방법
# 케라스 모델 훈련 전 compile() 메서드 수행
print(train_target[:10])
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')[7 3 5 8 6 9 3 3 9 9]
# 모델 훈련
model.fit(train_scaled, train_target, epochs=5)Epoch 1/5 1500/1500 [==============================] - 2s 1ms/step - loss: 0.6031 - accuracy: 0.7958 Epoch 2/5 1500/1500 [==============================] - 1s 990us/step - loss: 0.4744 - accuracy: 0.8385 Epoch 3/5 1500/1500 [==============================] - 1s 983us/step - loss: 0.4505 - accuracy: 0.8468 Epoch 4/5 1500/1500 [==============================] - 2s 1ms/step - loss: 0.4368 - accuracy: 0.8525 Epoch 5/5 1500/1500 [==============================] - 2s 1ms/step - loss: 0.4290 - accuracy: 0.8549
# 검증 세트를 사용하여 모델 성능 평가
model.evaluate(val_scaled, val_target)375/375 [==============================] - 0s 862us/step - loss: 0.4459 - accuracy: 0.8518 [0.4459433853626251, 0.8518333435058594]
심층 신경망
2개의 층
from tensorflow import keras
from sklearn.model_selection import train_test_split
# 케라스 API로 패션 MNIST 데이터셋 불러오기
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
# 이미지 픽셀값을 0~255 범위에서 0~1 사이로 변환
train_scaled = train_input / 255.0
# 28 x 28 크기의 2차원 배열을 784 크기의 1차원 배열로 펼치기
train_scaled = train_scaled.reshape(-1, 28*28)
# 훈련세트와 검증세트로 나누기
train_scaled, val_scaled, train_target, val_target = train_test_split(train_scaled, train_target, test_size=0.2, random_state=42)
- 은닉층(hidden layer)
- 입력층과 출력층 사이에 있는 모든 층
- 다양한 활성화 함수를 적용할 수 있으며, 대표적으로
시그모이드 함수,렐구(ReLU) 함수등을 사용한다.
# 시그모이드 함수를 사용한 은닉층
dense1 = keras.layers.Dense(100, activation='sigmoid', input_shape=(784,))
# 소프트맥스 함수를 사용한 은닉층
dense2 = keras.layers.Dense(10, activation='softmax')심층 신경망 만들기
- 앞서 만든 dense1, dense2 객체를 Sequential 클래스에 추가하여 심층 신경망(DNN, Deep Neural Network)을 만든다.
- 인공 신경망은 여러 개의 층을 추가하여 입력 데이터에 대해 연속적인 학습을 진행함으로써 강력한 성능을 얻는다.
model = keras.Sequential([dense1, dense2])
model.summary()Model: "sequential_1" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense_1 (Dense) (None, 100) 78500 dense_2 (Dense) (None, 10) 1010 ================================================================= Total params: 79510 (310.59 KB) Trainable params: 79510 (310.59 KB) Non-trainable params: 0 (0.00 Byte) _________________________________________________________________
- Layer (type)
- 층 이름
- 층을 만들 때 name 매개변수로 이름 지정 가능
- Output Shape
- 첫 번째 차원은 "샘플의 개수"를 나타내는데 None이다. 케라스 모델 훈련 시
미니배치 경사 하강법을 사용하고, 배치크기를 조정할 수 있기 때문에 샘플 개수를 고정할 수 없어 None으로 설정한다. - 두 번째 차원은 은닉층의 뉴런 개수이다.
- 첫 번째 차원은 "샘플의 개수"를 나타내는데 None이다. 케라스 모델 훈련 시
- Param #
- 모델 파라미터 개수
- dense1 : 입력 픽셀 784개 x 100개의 조합 + 100개의 절편 = 78,500개
- dense2 : 100개의 뉴런 x 10개의 조합 + 10개의 절편 = 1,010개
층을 추가하는 다른 방법
# Sequential 클래스 생성자 안에서 Dense 클래스 객체를 생성하여 전달하는 방법
model = keras.Sequential([
keras.layers.Dense(100, activation='sigmoid', input_shape=(784,)),
keras.layers.Dense(10, activation='softmax', name='output')
], name='패션 MNIST 모델')
model.summary()Model: "패션 MNIST 모델" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense_3 (Dense) (None, 100) 78500 output (Dense) (None, 10) 1010 ================================================================= Total params: 79510 (310.59 KB) Trainable params: 79510 (310.59 KB) Non-trainable params: 0 (0.00 Byte) _________________________________________________________________
# add() 메서드를 사용하는 방법
model = keras.Sequential()
model.add(keras.layers.Dense(100, activation='sigmoid', input_shape=(784,)))
model.add(keras.layers.Dense(10, activation='softmax'))
model.summary()Model: "sequential_2" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense_4 (Dense) (None, 100) 78500 dense_5 (Dense) (None, 10) 1010 ================================================================= Total params: 79510 (310.59 KB) Trainable params: 79510 (310.59 KB) Non-trainable params: 0 (0.00 Byte) _________________________________________________________________
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled, train_target, epochs=5)Epoch 1/5 1500/1500 [==============================] - 3s 2ms/step - loss: 0.5726 - accuracy: 0.8049 Epoch 2/5 1500/1500 [==============================] - 2s 1ms/step - loss: 0.4138 - accuracy: 0.8509 Epoch 3/5 1500/1500 [==============================] - 2s 1ms/step - loss: 0.3802 - accuracy: 0.8621 Epoch 4/5 1500/1500 [==============================] - 2s 1ms/step - loss: 0.3577 - accuracy: 0.8705 Epoch 5/5 1500/1500 [==============================] - 2s 2ms/step - loss: 0.3391 - accuracy: 0.8770
렐루(ReLU) 함수
- 시그모이드 함수의 단점
- 초창기 인공 신경망의 은닉층에는 활성화 함수로 시그모이드 함수를 많이 사용
- 오른쪽, 왼쪽 끝으로 갈수록 그래프가 누워있기 때문에 올바른 출력을 만들수 없음
- 렐루 함수
max(0, z)- 입력이 양수일 경우 활성화 함수가 없는 것처럼 그냥 입력을 통과
- 입력이 음수일 경우 0으로 만듬
- 심층 신경망에서 뛰어나고, 특히 이미지 처리에 좋은 성능을 낸다.
model = keras.Sequential()
# Flatten 클래스를 사용하여 입력 차원을 모두 일렬로 펼치기
model.add(keras.layers.Flatten(input_shape=(28, 28)))
# 활성화 함수로 ReLU 함수 사용
model.add(keras.layers.Dense(100, activation='relu'))
model.add(keras.layers.Dense(10, activation='softmax'))
model.summary()Model: "sequential_3" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= flatten (Flatten) (None, 784) 0 dense_6 (Dense) (None, 100) 78500 dense_7 (Dense) (None, 10) 1010 ================================================================= Total params: 79510 (310.59 KB) Trainable params: 79510 (310.59 KB) Non-trainable params: 0 (0.00 Byte) _________________________________________________________________
# 2차원 배열을 펼치는 작업은 제외하고 다시 훈련
from tensorflow import keras
from sklearn.model_selection import train_test_split
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
train_scaled = train_input / 255.0
train_scaled, val_scaled, train_target, val_target = train_test_split(train_scaled, train_target, test_size=0.2, random_state=42)
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled, train_target, epochs=5)
print("=> 활성화 함수로 시그모이드 함수를 사용했을 때 보다 렐루 함수를 사용할 때 약간의 성능 향상이 있음")Epoch 1/5 1500/1500 [==============================] - 2s 1ms/step - loss: 0.5302 - accuracy: 0.8127 Epoch 2/5 1500/1500 [==============================] - 2s 1ms/step - loss: 0.3924 - accuracy: 0.8589 Epoch 3/5 1500/1500 [==============================] - 2s 1ms/step - loss: 0.3531 - accuracy: 0.8732 Epoch 4/5 1500/1500 [==============================] - 2s 1ms/step - loss: 0.3328 - accuracy: 0.8808 Epoch 5/5 1500/1500 [==============================] - 3s 2ms/step - loss: 0.3152 - accuracy: 0.8877 => 활성화 함수로 시그모이드 함수를 사용했을 때 보다 렐루 함수를 사용할 때 약간의 성능 향상이 있음
# 검증 세트로 성능 확인
model.evaluate(val_scaled, val_target)375/375 [==============================] - 0s 1ms/step - loss: 0.3385 - accuracy: 0.8797 [0.3384510278701782, 0.8796666860580444]
옵티마이저
- 신경망에는 하이퍼파라미터가 많이 존재한다.
- 위 예제에서 지정해야 하는 하이퍼파라미터 목록
- 은닉층의 개수
- 은닉층의 뉴런 개수
- 활성화 함수
- 층의 종류
- 배치 사이즈 매개변수
- 에포크 매개변수
- 옵티마이저
- 옵티마이저(optimizer)
- 케라스는 다양한 종류의 경사 하강법 알고리즘을 제공
compile()메서드에서는 기본 경사 하강법 알고리즘인RMSprop을 사용
# 옵티마이저로 확률적 경사 하강법 사용
model.compile(optimizer='sgd', loss='sparse_categorical_crossentropy', metrics='accuracy')
- 기본 경사 하강법 옵티마이저
sgd = keras.optimizers.SGD(learning_rate=0.01, momentum=0, nesterov=False)- 모멘텀 최적화(momentum optimization)
- momentum 매개변수를 0보다 큰 값으로 지정
- 네스테로프 모멘텀 최적화(nesterov momentum optimization)
- nesterov 매개변수를 True로 설정
- 모멘텀 최적화를 2번 반복하여 구현
- 모멘텀 최적화(momentum optimization)
- 적응적 학습률 옵티마이저
- 적응적 학습률(adaptive learning rate)
- 모델이 최적점에 가까이 갈수록 학습률을 낮출 수 있고, 이로 인해 안정적으로 최적점에 수렴할 가능성이 높아지는 학습률
- 대표적인 옵티마이저
- Adagrad
- RMSprop
- 적응적 학습률(adaptive learning rate)
- Adam
- 모멘텀 최적화와 RMSprop의 장점을 접목
# 옵티마이저로 Adam 사용
model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape=(28, 28)))
model.add(keras.layers.Dense(100, activation='relu'))
model.add(keras.layers.Dense(10, activation='softmax'))
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled, train_target, epochs=5)Epoch 1/5 1500/1500 [==============================] - 3s 2ms/step - loss: 0.5289 - accuracy: 0.8162 Epoch 2/5 1500/1500 [==============================] - 2s 2ms/step - loss: 0.3954 - accuracy: 0.8587 Epoch 3/5 1500/1500 [==============================] - 2s 2ms/step - loss: 0.3529 - accuracy: 0.8726 Epoch 4/5 1500/1500 [==============================] - 4s 2ms/step - loss: 0.3258 - accuracy: 0.8804 Epoch 5/5 1500/1500 [==============================] - 2s 2ms/step - loss: 0.3041 - accuracy: 0.8878
model.evaluate(val_scaled, val_target)375/375 [==============================] - 0s 1ms/step - loss: 0.3683 - accuracy: 0.8632 [0.36832520365715027, 0.8631666898727417]
신경망 모델 훈련
손실 곡선
# 패션 MNSIT 데이터셋 적재 및 훈련 서트와 검증 세트로 나누기
from tensorflow import keras
from sklearn.model_selection import train_test_split
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
train_scaled = train_input / 255.0
train_scaled, val_scaled, train_target, val_target = train_test_split(train_scaled, train_target, test_size=0.2, random_state=42)# 모델을 만드는 함수 정의
def model_fn(a_layer=None):
model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape=(28, 28)))
model.add(keras.layers.Dense(100, activation='relu'))
if a_layer:
model.add(a_layer)
model.add(keras.layers.Dense(10, activation='softmax'))
return model# a_layer 매개변수를 전달하지 않고 model_fn() 함수 호출
model = model_fn()
model.summary()Model: "sequential_5" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= flatten_2 (Flatten) (None, 784) 0 dense_10 (Dense) (None, 100) 78500 dense_11 (Dense) (None, 10) 1010 ================================================================= Total params: 79510 (310.59 KB) Trainable params: 79510 (310.59 KB) Non-trainable params: 0 (0.00 Byte) _________________________________________________________________
# 모델 훈련
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
history = model.fit(train_scaled, train_target, epochs=5, verbose=0)# history 객체 내 훈련 측정값 확인
print(history.history.keys())dict_keys(['loss', 'accuracy'])
# history 속성에 포함된 loss(손실) 값을 그래프로 출력
import matplotlib.pyplot as plt
plt.plot(history.history['loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()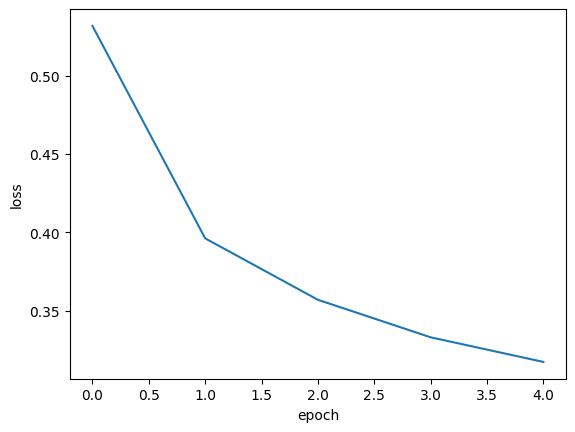
# history 속성에 포함된 accuracy(정확도) 값을 그래프로 출력
plt.plot(history.history['accuracy'])
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.show()
# epoch 횟수를 20으로 늘려서 모델을 훈련하고 손실/정확도 그래프 출력
model = model_fn()
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
history = model.fit(train_scaled, train_target, epochs=20, verbose=0)
fig, axs = plt.subplots(1, 2, figsize=(10, 5))
axs[0].plot(history.history['loss'])
axs[0].set_xlabel('epoch')
axs[0].set_ylabel('loss')
axs[1].plot(history.history['accuracy'])
axs[1].set_xlabel('epoch')
axs[1].set_ylabel('accuracy')
plt.show()
검증 손실
- epoch에 대한 과대적합/과소적합을 파악하려면
훈련 세트와검증 세트의 점수를 모두 확인해봐야 한다. - 단, 인공 신경망에서는 손실이 감소해도 정확도가 높아지지 않는 경우가 존재하기 때문에 정확도 보단
손실 함수의 값을 확인하는 것이 더 좋다.
# fit() 함수의 validation_data 매개변수에 검증 데이터 전달
model = model_fn()
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
history = model.fit(train_scaled, train_target, epochs=20, verbose=0, validation_data=(val_scaled, val_target))# history 값 확인
print(history.history.keys())
print("=> 훈련 세트에 대한 손실과 정확도는 loss, accuracy에 들어있고 테스트 세트에 대한 값은 val_loss, val_accuracy에 들어있다.")dict_keys(['loss', 'accuracy', 'val_loss', 'val_accuracy']) => 훈련 세트에 대한 손실과 정확도는 loss, accuracy에 들어있고 테스트 세트에 대한 값은 val_loss, val_accuracy에 들어있다.
# 훈련 세트 및 검증 세트에 대한 손실 그래프
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()
# (기본값 RMSprop 옵티마이저 대신) Adam 옵티마이저를 적용하여 훈련 세트 및 검증 세트에 대한 손실 그래프 그리기
model = model_fn()
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
history = model.fit(train_scaled, train_target, epochs=20, verbose=0, validation_data=(val_scaled, val_target))
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()
from keras.callbacks import ReduceLROnPlateau
# 학습률을 조절하여 재시도
# - https://keras.io/api/callbacks/reduce_lr_on_plateau/
model = model_fn()
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics='accuracy'
)
reduceLR = ReduceLROnPlateau(
monitor='val_loss', # 검증 손실을 기준으로 callback이 호출됩니다
factor=0.1, # callback 호출시 학습률을 1/2로 줄입니다
patience=2, # epoch 10 동안 개선되지 않으면 callback이 호출됩니다
)
history = model.fit(
x=train_scaled,
y=train_target,
epochs=20,
verbose=0,
validation_data=(val_scaled, val_target),
callbacks=[reduceLR]
)
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()
드롭아웃(dropout)
- 훈련 과정에서 층에 있는 일부 뉴런을
랜덤하게 꺼서일부 뉴런에 의존하는 것을 막고, 마치 많은 신경망을앙상블 하는 효과를 내서 과대적합을 막는 방법 랜덤하게 끄다의 의미- 뉴런의 출력을 0으로 만들다
- 즉, dropout 하다
- 얼마나 많은 뉴런을 dropout 해야 할지에 대한 값은 하이퍼파라미터이다.
- 케라스는 드롭아웃을 층으로 제공 : keras.layers.Dropout
- 텐서플로와 케라스는 모델을 평가와 예측에 사용할 때는 자동으로 드롭아웃을 적용하지 않는다.
# model_fn() 함수에 드롭아웃 객체를 전달하여 모델을 생성하고 확인
model = model_fn(keras.layers.Dropout(0.3))
model.summary()Model: "sequential_10" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= flatten_7 (Flatten) (None, 784) 0 dense_20 (Dense) (None, 100) 78500 dropout (Dropout) (None, 100) 0 dense_21 (Dense) (None, 10) 1010 ================================================================= Total params: 79510 (310.59 KB) Trainable params: 79510 (310.59 KB) Non-trainable params: 0 (0.00 Byte) _________________________________________________________________
# 드롭아웃 적용한 모델 훈련
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
history = model.fit(train_scaled, train_target, epochs=20, verbose=0, validation_data=(val_scaled, val_target))# 훈련 손실 및 검증 손실 그래프 그리기
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()
모델 저장과 복원
- save_weights()
- 훈련된 모델의 파라미터를 저장
- 기본적으로 텐서플로의 체크포인트 포맷으로 저장
- 확장자를 '.h5'로 지정하면 HDF5 포맷으로 저장
- save()
- 모델 구조와 모델 파라미터를 함께 저장
- 기본적으로 텐서플로의 SavedModel 포맷으로 저장
- 확장자를 '.h5'로 지정하면 HDF5 포맷으로 저장
- load_weights()
- load_model()
# 과대적합이 되지 않는 만큼 epoch 횟수를 10으로 줄여서 모델 훈련
model = model_fn(keras.layers.Dropout(0.3))
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
history = model.fit(train_scaled, train_target, epochs=10, verbose=0, validation_data=(val_scaled, val_target))# 모델 파라미터 저장
model.save_weights('model-weights.h5')# 모델 구조 및 모델 파라미터 저장
model.save('model-whole.h5')# 생성된 파일 확인
!ls -al *.h5-rw-r--r-- 1 root root 333320 Feb 18 09:03 model-weights.h5 -rw-r--r-- 1 root root 981176 Feb 18 09:03 model-whole.h5
# 실험 1) 훈련하지 않은 새로운 모델 생성 > model-weights.h5 파일에서 훈련된 모델 파라미터를 읽어 사용하기
model = model_fn(keras.layers.Dropout(0.3))
model.load_weights('model-weights.h5')
import numpy as np
val_labels = np.argmax(model.predict(val_scaled), axis=-1)
print(f"정확도 : {np.mean(val_labels == val_target)}")375/375 [==============================] - 0s 980us/step 정확도 : 0.8806666666666667
# 실험 2) model-whole.h5 파일에서 새로운 모델을 만들어 바로 사용하기
model = keras.models.load_model('model-whole.h5')
model.evaluate(val_scaled, val_target)375/375 [==============================] - 0s 1ms/step - loss: 0.3319 - accuracy: 0.8807 [0.3319183886051178, 0.8806666731834412]
콜백(callback)
- 훈련 과정 중간에 어떤 작업을 수행할 수 있게 하는 객체
- keras.callbacks 패키지 아래에 클래스 존재
fit()메서드의 callbacks 매개변수에 리스트로 전달하여 사용- 콜백 종류 (일부)
- ModelCheckpoint 콜백 : epoch마다 모델을 저장하거나 save_best_only 매개변수를 True로 지정하여 가장 낮은 검증 점수를 만드는 모델을 저장할 수 있다.
- EarlyStopping 콜백 : 과대적합이 시작되기 전에 훈련을 미리 중지한다. restore_best_weights 매개변수를 True로 지정하면 가장 낮은 손실을 낸 모델 파라미터로 되돌린다.
# ModelCheckpoint 콜백 적용하여 가장 낮은 검증 점수를 만드는 모델 저장
model = model_fn(keras.layers.Dropout(0.3))
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
checkpoint_callback = keras.callbacks.ModelCheckpoint('best-model.h5', save_best_only=True)
model.fit(
train_scaled,
train_target,
epochs=20,
verbose=0,
validation_data=(val_scaled, val_target),
callbacks=[checkpoint_callback]
)# 저장된 모델을 읽어서 예측 수행
model = keras.models.load_model('best-model.h5')
model.evaluate(val_scaled, val_target)375/375 [==============================] - 0s 1ms/step - loss: 0.3129 - accuracy: 0.8876 [0.3129093647003174, 0.887583315372467]
# ModelCheckpoint 콜백과 EarlyStopping 콜백을 적용
model = model_fn(keras.layers.Dropout(0.3))
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
checkpoint_callback = keras.callbacks.ModelCheckpoint('best-model.h5', save_best_only=True)
early_stopping_callback = keras.callbacks.EarlyStopping(patience=2, restore_best_weights=True)
model.fit(
train_scaled,
train_target,
epochs=20,
verbose=0,
validation_data=(val_scaled, val_target),
callbacks=[checkpoint_callback, early_stopping_callback]
)print(f"조기 종료가 된 epoch : {early_stopping_callback.stopped_epoch}")조기 종료가 된 epoch : 8
# 손실 그래프 확인
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()
# 검증 세트로 성능 확인
model.evaluate(val_scaled, val_target)375/375 [==============================] - 0s 1ms/step - loss: 0.3283 - accuracy: 0.8788 [0.32828083634376526, 0.8787500262260437]
반응형
'프로그래밍 > AI' 카테고리의 다른 글
| [혼공머신 11기] 혼공학습단 11기 활동 회고 (1) | 2024.02.18 |
|---|---|
| [혼공머신 11기] 5주차 스터디 및 과제 (1) | 2024.02.03 |
| [혼공머신 11기] 4주차 스터디 및 과제 (1) | 2024.01.28 |
| [혼공머신 11기] 3주차 스터디 및 과제 (0) | 2024.01.20 |
| [혼공머신 11기] 2주차 스터디 및 과제 (1) | 2024.01.13 |


